Welcome to litan's blog
这是我的教育技术学习小天地-
一行代码实现数据标准化
数据标准化有助于提升机器学习模型准确度。本文对数据集中某列数据进行标准化处理。采用min-max方式。
from sklearn import preprocessing minmax = preprocessing.MinMaxScaler() data[['学科A','学科B','学科C','学科D']] = minmax.fit_transform(data[['学科A','学科B','学科C','学科D']])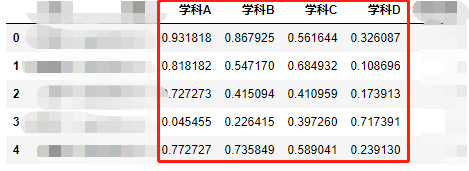

-
python将数据集中文本标签替换成数值型
数据科学中经常出现的标签为文本型的,因为需要转化为数值型,以便后续处理。
1.读取数据
import pandas as pd data = pd.read_csv('all_data.txt',delimiter='\t') data.head()
2.对标签列进行替换
data_class={'否':0,'是':1} data['是否过线']=data['是否过线'].map(data_class)

-
python将excel表内空值替换成特征数值
python进行表格处理时,经常遇到空值需要做特定替换,pandas专门提供了这样的功能。
fillna()方法
函数形式:fillna(value=None, method=None, axis=None, inplace=False, limit=None, downcast=None, **kwargs)[^1]
- value:用于填充的空值的值。
- method: {‘backfill’, ‘bfill’, ‘pad’, ‘ffill’, None}, default None。定义了填充空值的方法, pad / ffill表示用前面行/列的值,填充当前行/列的空值, backfill / bfill表示用后面行/列的值,填充当前行/列的空值。
- axis:轴。0或’index’,表示按行删除;1或’columns’,表示按列删除。
- inplace:是否原地替换。布尔值,默认为False。如果为True,则在原DataFrame上进行操作,返回值为None。
- limit:int, default None。如果method被指定,对于连续的空值,这段连续区域,最多填充前 limit 个空值(如果存在多段连续区域,每段最多填充前 limit 个空值)。如果method未被指定, 在该axis下,最多填充前 limit 个空值(不论空值连续区间是否间断)
- downcast:dict, default is None,字典中的项为,为类型向下转换规则。或者为字符串“infer”,此时会在合适的等价类型之间进行向下转换,比如float64 to int64 if possible。
示例
matrix_data.fillna(value=0)替换前
 替换后
替换后
 [^1]: https://blog.csdn.net/qq_17753903/article/details/89892631
[^1]: https://blog.csdn.net/qq_17753903/article/details/89892631
-
通过神经网络预测学生成绩
本文重点介绍,基于神经网络,建立学生成绩预测模型。
1.神经网络
多层感知机(MLP,Multilayer Perceptron)也叫人工神经网络(ANN,Artificial Neural Network),除了输入输出层,它中间可以有多个隐层,最简单的MLP只含一个隐层,即三层的结构,如下图:
 对一些标记进行定义:
对一些标记进行定义:- $a^{(x)}_y$表示,第$x$层,第$y$个神经元;
- $b^{(x)}_y$表示对每个维度输出的偏置;
- $h_{w,b}$为神经网络输出
- $F^{(x)}$表示激活函数
1.1 输入层
该层主要为输入的特征,如输入的为$n$维度特征,则输入层就有$n$个神经元。在此我们将输入特征,向量化为$X$,则: $X=[x_{1},x_{2}…x_{n}]$
1.2 隐藏层
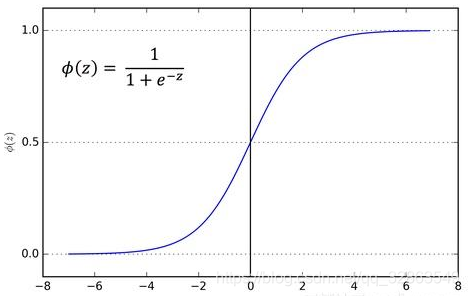
如上图所示,为隐藏层为全连接形式,该层输入为Input Layer的输出。其中$a^{(2)}{1},a^{(2)}{2},a^{(2)}_{2}$数值的计算方法为: 其中,$F^{(1)}$为第一层激活函数,一般为$Sigmoid$函数,该函数定义形式如下: $Sigmoid$函数是一个在生物学中常见的$S$型函数,也称为$S$型生长曲线。在信息科学中,由于其单增以及反函数单增等性质,$Sigmoid$函数常被用作神经网络的阈值函数,将变量映射到0,1之间。图像如下:
1.3 输出层
该层$h_{w,b}$计算形式如下:
2 实验
2.1 软硬件环境描述
- 软件:SPSS MODELER SUBSCRIPTION
- 系统:WIndows 10
2.2 数据描述
- 文件名:StudentPerformance.xlsx
- 数据量:480个样本,其中特征16个
2.3 实验过程
2.3.1 读取数据
 如上图,从源中选取“Excel”节点,拖动至主界面,导入数据。
如上图,从源中选取“Excel”节点,拖动至主界面,导入数据。
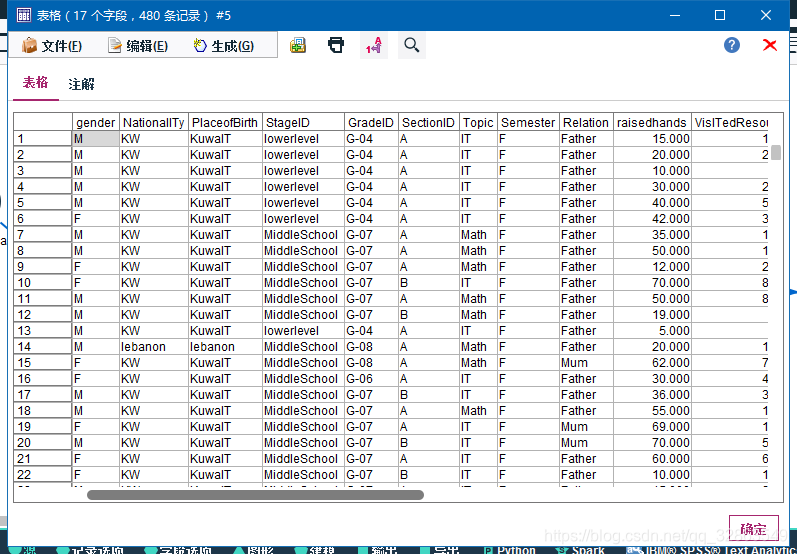
 使用“表格”节点查看数据:
使用“表格”节点查看数据:
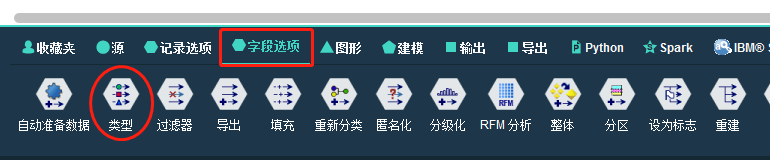
2.3.2 数据类型
在字段选项中选择类型。
 并和EXCEL数据源建立连接
并和EXCEL数据源建立连接
 将Class字段设置为目标。
将Class字段设置为目标。

2.3.3 检查数据质量
 对质量选项卡进行检查
对质量选项卡进行检查
 发现:当前数据质量较好,不存在离群值和极值,因此不需要进一步处理。
发现:当前数据质量较好,不存在离群值和极值,因此不需要进一步处理。
2.3.4 特征选择
为了得到高质量模型,对贡献度较高的特征进行提取,对贡献度较低的特征删除处理。在建模中选择特征选择。
 分析发现:StageID和SectionID特征相关性较小,因此在建模时不做选择。
分析发现:StageID和SectionID特征相关性较小,因此在建模时不做选择。
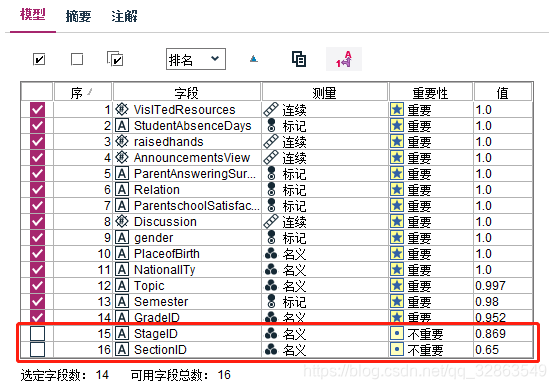
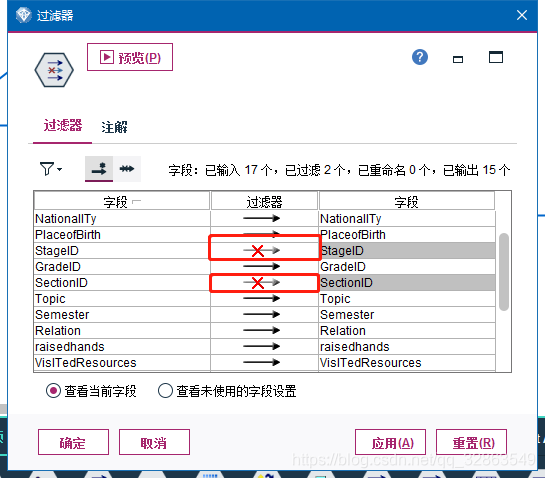
2.3.5 过滤掉相关性较小特征
 在箭头上勾画出 X。
在箭头上勾画出 X。
2.3.6 划分训练和测试集
在字段选项中选择分区节点。
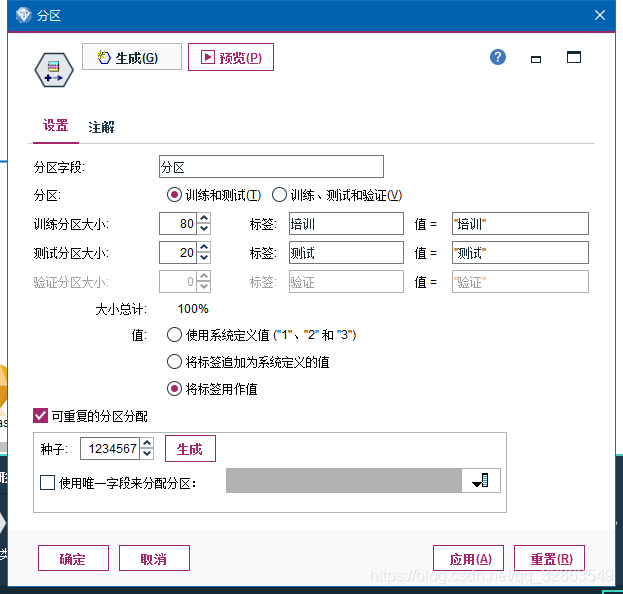
 对分区进行设置,其中80%最为训练集,20作为测试集。
对分区进行设置,其中80%最为训练集,20作为测试集。
2.3.7
在建模下面选择神经网络。
 并进行设置:
在构建选项中基本选择多层感知器(MLP)。
并进行设置:
在构建选项中基本选择多层感知器(MLP)。
 对模型过拟合程度进行限定,防止过拟合。
对模型过拟合程度进行限定,防止过拟合。
 最后进行模型训练,结果如下:
最后进行模型训练,结果如下:
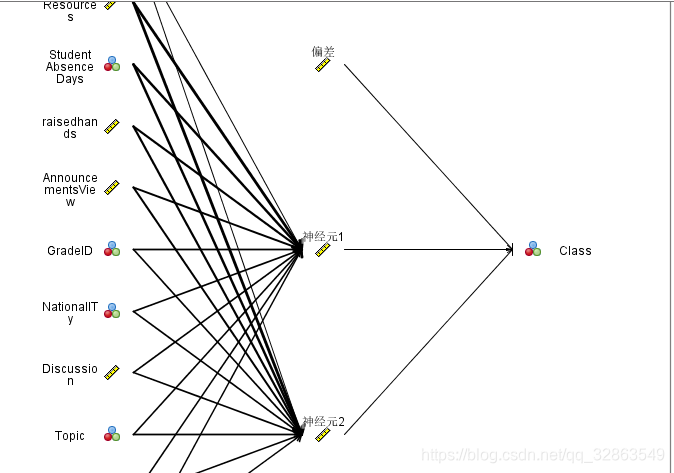
 多层感知机模型图:
多层感知机模型图:
2.3.8 准确度分析
在输出中选择分析
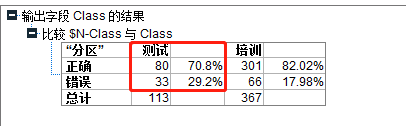
 得到该模型测试准确度为70.8%。
得到该模型测试准确度为70.8%。

3.遇到个怪事
在截图向CSDN中粘贴时,返回的是一张我从来没见过的图。这是咋回事?我本人不做JAVA,不清楚是不是别人和我同时向CSDN粘贴图片导致的这个问题!由于不做Web不理解这个错误可能是什么原因导致的,现在留在这里!也许有人能解答!

-
交叉验证的实现与热力图可视化实现
当通过小样本训练机器学习模型时,为了更加准确的评价机器学习模型,可以采用k折交叉验证方法
1.读取训练数据
mldata_x = data[['学科A','学科B','学科C','学科D']] mldata_y = data[['学业成败']]2.进入5折交叉验证方法
```python from sklearn.model_selection import cross_val_score nb=GaussianNB() score=cross_val_score(nb,mldata_x,mldata_y,cv=5,scoring=’accuracy’)#5折:交叉验证
print (‘平均准确率’,score.mean()) print (‘每则准确率’,score) ```
3.扫码获取更多学习资料

-
通过python实现神经网络算法
本文将介绍基于sklearn实现MLP(多层感知机)算法的过程。
1.读取训练数据
mldata_x = data[['学科A','学科B','学科C','学科D']] mldata_y = data[['学业成败']]2.划分训练数据集和测试数据集
from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(mldata_x, mldata_y, test_size = 0.2, random_state = 10)3.模型训练与评价
from sklearn.neural_network import MLPClassifier mp= MLPClassifier(solver='lbfgs', alpha=1e-5,hidden_layer_sizes=(5,2), random_state=1) mp.fit(X_train, y_train) MLPClassifier(activation='relu', alpha=1e-05, batch_size='auto', beta_1=0.9, beta_2=0.999, early_stopping=False, epsilon=1e-08, hidden_layer_sizes=(5, 2), learning_rate='constant', learning_rate_init=0.001, max_iter=200, momentum=0.9, nesterovs_momentum=True, power_t=0.5, random_state=1, shuffle=True, solver='lbfgs', tol=0.0001, validation_fraction=0.1, verbose=False, warm_start=False) Predict = mp.predict(X_test) mp_Score = accuracy_score(y_test,Predict) mp_Score4.扫码获取更多学习资料
