教育研究中,经常对一个或者多个文本进行词频统计分析,用以反映该文本的主题。本文首先介绍利用oset开源库中提供的wordcount()函数实现的字符统计简单调用方式(第2小节);随后解析wordcount()函数源代码以及其中的一些知识点(第3小节)。
1.文件夹内容展示
该文件夹中分别包含“教育学部.txt”,“心理学部.txt”等单个文件。我们将利用oset库中wordcount函数实现对单个文件或者多个文件的字符统计处理。
2.词频统计
oset库可以自动识别是对单个文件还是多个文件进行操作。因此研究者在实际应用中无需分别调用两个函数实现单个和多个文件词频统计,仅仅调用wordcount()函数即可,十分方便。
2.1单个文件词频统计
2.1.1 调用形式
from oset import Chineseword Chineseword.wordcount('C:\\Users\\Administrator\\Desktop\\test\\教育学部.txt')返回结果:
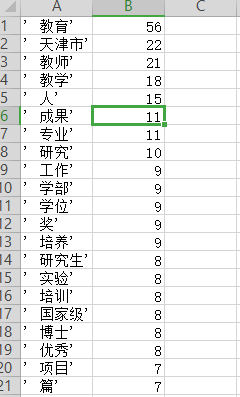
2.1.2 运行结果
2.2 多文件词频统计
2.2.1 调用形式
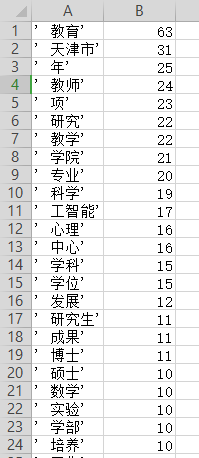
from oset import Chineseword Chineseword.wordcount('C:\\Users\\Administrator\\Desktop\\test')2.2.2 运行结果
3.源码解析
def wordcount(filepath): '''try---except---部分为了判断传入的地址是指向单个 文件还是文件夹,如果是文件夹,则首先需要对所有文件进行 合并并读取出来。''' try: File.combfile(filepath) sentence=File.readfile(filepath+'\\combfile_Fin.txt') os.remove(filepath+'\\combfile_Fin.txt') #os.remove在这里起到对产生的临时文件进行清除的作用 except: sentence=File.readfile(filepath) filepath = os.path.dirname(filepath) sentence=Chineseword.cutword(sentence) worddict=Chineseword.sentencecount(sentence) worddict=sorted(worddict.items(), key = lambda kv:(kv[1], kv[0]),reverse=True) #sorted是对字典进行排序,默认为升序,则reverse=True ##表示降序 wordcount_csv = open(filepath+'/osetwordcount.csv','w+') for key_value in worddict: wordcount_csv.write(str(key_value)[1:-1]+'\n') #此处[1:-1]是对强制类型转化为str后的文本进行 #处理去除前后的括号() print("统计完毕,文件已经输出到:"+filepath+"\osetwordcount.csv文件中")4.声明
上述原码来源于我编写的oset开源库,该库旨在帮助教育研究者便捷处理日常科研、工作中遇到的问题。

作为一名非科班出身的教育技术学研究生,技术水平十分有限。近期看到教育工作者在处理数据是比较困难,包括本教育技术学的科研工作者在面对大批量数据时也是束手无策,于是萌生了为教育工作者写一个开源库的想法,意图通过简单的几行代码就可以完成诸如文件合并、字符云等复杂功能。欢迎关注该项目,如果有同学在此方面感兴趣和可以和我联系,我们一起维护该项目! 本人感兴趣的研究方向:复杂系统计算与可解释性的深度学习以及自然语言处理。微信公众号:SMNLP;个人博客:www.litan.tech。